Monitor & Improve CI/CD Pipeline

Project Overview
I was tasked with reducing the high costs of the company’s cloud-based CI/CD runners, which were costing tens of thousands a year. Despite my lack of experience in CI/CD pipelines and DevOps, I gathered necessary data and purchased server hardware to transition to an on-prem fixed cost model. I learned to install the runners on local servers, addressing storage and network bottlenecks, and created a dashboard using Azure Functions and PowerBI for developers to monitor service levels. Additionally, I scripted and automated server upgrades and provided a detailed cost analysis, demonstrating significant savings to management, achieving this within six months.
Approach & Plan
Current System
The current system at the time was a fast, but rather inefficient and costly cloud based runner system, running on a per-minute based CI/CD pipeline. The team was unsure why their CI/CD costs were so high, and tasked me with reducing the cost.
New System
I had never worked in a CI/CD pipeline, nor had previously worked in a DevOps position, but nonetheless, I went through a few iterations of designs as I was unsure which was the best method. This was a multi-stage project and one of the most complex projects I had worked on.
I had a few requirements among other things:
- It should decrease any additional purchase of CI/CD minutes to run projects.
- It should maintain similar runtimes for jobs or have a significant enough tradeoff on cost that the time spent waiting should not impact progress.
- The developers should be able to monitor metrics on the runners along with the failure rate, runtimes, and other aspects of their job.
Deployment
Within 3 months we had made the switch and was saving thousands each month and within 6 months I had:
- gathered the data required to make an informed decision,
- purchased the required server hardware that would reduce the cost to a fixed cost + basic maintenance,
- learned and set up the best methods to install the runners on the local servers, including storage and network bottleneck issues,
- produced a dashboard using PowerBI that pulled API data and saved to an Azure Blob storage using Azure Functions that developers could monitor self-imposed service level requirements,
- scripted and automated server upgrades to maintain the latest updates,
- and provided cost analysis of the savings to managers.
Insight
The first thing I did was find a way to gather data from a host of locations including:
- VMs - to find their resource usage, so I could gauge the system requirements
- CI/CD Pipelines - to find runtimes of each job and pipeline that was being run.
- Source Control API - to gather bulk data from the API provided by the source control program.
I spent some time on getting a working model of what data was important and what KPIs I wanted to set for the new method.
There were a few changes I suggested to the CI/CD developer to ensure a switch to another system would not impact runtime too much and reduce the parallelization required for a local switch due to limitations on hardware availability.
Setup
I came up with a few solutions to reduce the cloud spend on the CI/CD pipelines.
One idea was using cloud based VMs that would run on a cloud VM. I found that it was about the same cost as paying for the minutes, mainly due to the parallelism required by each CI/CD pipeline, so we scratched that idea, instead using it as a backup and overflow option.
Another idea was using individual unused computers the business owned as runners, but found that the amount of jobs and overhead managing each individual computer would be too high.
Another idea was running in a Kubernetes environment. I was planning on deploying it to a self-hosted Kubernetes server, but found the complexity and maintenance to set up such a system would outweigh the benefits due to the size and management overhead of monitoring and implementing such a system.
The final system design I settled on was purchasing a new server that could run on-prem. The on-prem server required additional research because I had to analyze network traffic, CPU usage, RAM usage, parallelization requirement based on min, max and average jobs ran at any given time as I didn’t want a huge job queue because I miscalculated the amount of jobs running at peak time. The calculation was especially important because changing to the shared runners the source control service provided, required code changes to be pushed; this was untenable for short bursts of pending or queued max jobs especially at peak build times.
I did a test case on another smaller on-prem server and gathered more data from the source control API as well as a local Grafana & Prometheus instances to guage the job requirement impact on the on-prem infrastructure and came up with some data I was able to share with my manager. This included the opportunity cost, the current cost and yearly savings by switching to the on-prem server and the time to setup the server where the cost savings could be actualized.
My manager was happy by the research and asked me to talk to IT to purchase and deploy the required hardware. While we had to adjust the server purchase price because of some uncertainty in the purchase, we were able to move forward and purchase a different but similarly capable server that could actualize the cost savings earlier than I had planned, but required hardware upgrades if the savings were actualized earlier than planned. In the server research, I made sure the total required VMs required matched the specs of the server capability.
Once purchased, IT installed the server and set up the basic infrastructure and I installed the required software to run the source control runners, inculding Hyper-V, Docker, runner software, and other dependencies. I separated the runner software into multiple separate VMs so I could run update scripts on each one without taking all runners offline to update one VM. This also enabled me to run A/B tests on different runner configurations without disrupting other runners and allowed me to roll back changes in case the changes were not successful.
Test and Validation
I did some testing prior to releasing as an outage could cause major issues with the dev release schedule.
- I tested pipelines on the new server to determine hardware, network and runtime loads, as well as check baseline runtimes to make sure they aligned with expected values.
- I tested a few types of jobs to make sure the right dependencies were in place.
From joining the company, and never being part of a DevOps team, nor understanding a development pipeline to test & validation was about 3 months.
Change Management
There were a few things I did to manage the change:
- I alerted the devs of the change and asked them to let me know of any issues they ran into.
- I staged 2 other backup servers in case the server didn’t manage the load well.
- I staged commits ready to roll back the change completely in case the server completely failed.
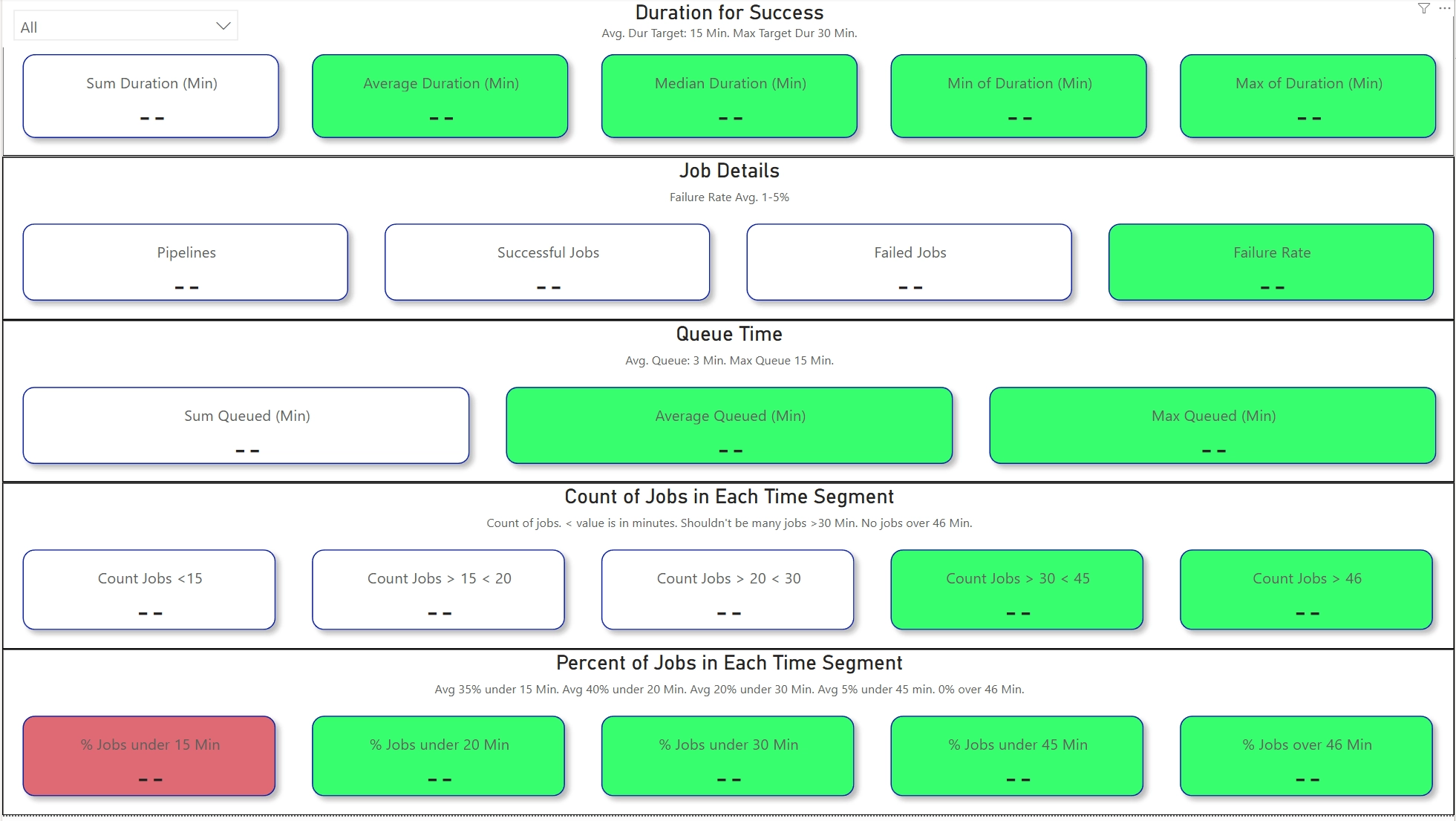
- Duration, Average Duration, Median Duration, Min & Max Duration (to determine outliers)
- Total Pipelines, Successful Jobs, Failed Jobs, Failure Rate
- Queued Jobs, Average Queue Duration, Max Queue Duration
- Jobs in timed blocks (to see spread of jobs across the runtime)
- Percent of jobs in each time blocks (to find a bell curve and outliers)
- Runtime over each server & runner (to make sure a configuration wasn’t causing longer runtimes on one runner)
- Job taken by each runner (to ensure we were maintaining runner spread of jobs)
- Jobs by employee (to make sure failures reported by an employee wasn’t an outlier)
I created SLA’s from the data flows I set up earlier on the server and the source control API to monitor runtime and performance. Here’s some screenshots of the data I was collecting, with no data in there (obviously). Some of the data included:
Because of the research and planning along with setting up contingencies, the roll out went smoothly with only a few minor adjustments needed.
Collaboration & Continuous Changes
I worked with the devs to find improvements to jobs and pipelines and made some further changes. The key changes was improving server efficiency by more than 20% and reducing queue time by almost 40%. I also improved insights to make sure we were alerted on server outages.
- Adjusted the storage of dependencies to reduce network noise and external bandwidth usage. I did this by monitoring storage usage and average download time for each job. I found that a pipeline could saturate external network bandwidth at full load, slowing other jobs down, so switched to an internal object storage service to reduce bandwidth.
- Deciphered an odd issue where the median job runtime would slightly increase but a small portion of jobs would time out when the server was under heavy load. I found the server hard drives IOPS were completely saturated. Requested the change to higher speed drives reduced timeout rate by almost 10%.
- I decreased individual VM RAM and CPU usage requirement, which allowed me to increase the total jobs able to run in parallel by more than 20%.
- I wrote upgrade scripts for each VM that could automatically update, reboot the VM and ping back to the source control it was ready for new jobs.
- I wrote another upgrade script that could delete unused dependencies on a regular basis to decrease storage space on the server.
- I tightened the data feedback loop on the server so I was able to get close to realtime data
- Via another script in Azure Logic Apps, I was able to grab and store the data from the source control API to store the data for 60 days so we could see historical data on how the runner was performing.
- Via PowerBI, I was able to transform the data into actionable stats I shared with the team to make further adjustments to the DevOps pipeline, as well as create improved KPIs to show objective feedback when devs shared concern for slower runtimes.
- I used Grafana to create alerts in Slack for storage size, down detection and other important metrics that could impact server functionality.
Final Results
Within 3 months we had made the switch and was saving thousands each month and within 6 months I had:
- gathered the data required to make an informed decision,
- purchased the required server hardware that would reduce the cost to a fixed cost + basic maintenance,
- learned and set up the best methods to install the runners on the local servers, including storage and network bottleneck issues,
- produced a dashboard using PowerBI that pulled API data and saved to an Azure Blob storage using Azure Functions that developers could monitor self-imposed service level requirements,
- scripted and automated server upgrades to maintain the latest updates,
- and provided cost analysis of the savings to managers.
I was given little direction and was told the success metric was reducing the cost of the runners.
The development team praised the work I did and the smoothness of the transition as it required little to no effort for them to make the switch and my manager was happy to report a cost reduction in CI/CD costs.





Member discussion